
Autor: Simon Ostermann
Technologie-Steckbrief
Einleitung
Die Technologien des Information Retrieval (Informationsextraktion) und der intelligenten Suche sind weit verbreitete Technologien der maschinellen Sprachverarbeitung. Information Retrieval ist eine Technologie, mit Hilfe derer auf Grundlage einer Query (Suchanfrage) aus einer großen Datenmenge Informationen extrahiert werden können. Die intelligente (oder auch semantische) Suche ist eine konkrete Anwendung des Information Retrieval, bei der die Query in der Regel in Form von Schlüsselbegriffen oder natürlicher Sprache formuliert wird. Die Datenmenge besteht in der Regel aus einer großen Textdatenbank oder einer Reihe von Websiten im Internet. In diesem Artikel beleuchten wir die grundlegende Technologie, die von Information-Retrieval-Modellen und -Algorithmen insbesondere im Bereich der intelligenten Suche verwendet wird.
Beschreibung der KI-Technologie & KI-Methode/n/-Komponenten
Klassische Ansätze.
Eine Grundlage für die meisten modernen und klassischen Ansätze des Information Retrieval ist eine computerlinguistische Vorverarbeitung (Preprocessing) der zu durchsuchenden Texte. Hierzu zählt beispielsweise die Tokenisierung, d.h. das Aufteilen eines Textes in Wörter. Darüber hinaus werden die Wörter in ihre Grundform abgeleitet(lemmatisiert): : aus „Die Regierung hat eine Reihe neuer Gesetze verabschiedet“ wird so „der, Regierung, haben, ein, Reihe, neu, Gesetz, verabschieden“. Darüber hinaus kann ein Stemming erfolgen, welches zum Ziel hat, Wortstämme abzuleiten, das heißt Wortendungen „wegzukürzen“. Aus dem Beispielsatz würde so „der, Regierung, hab, ein, Reih, neu, Gesetz, verabschied“. Auf Basis dieser Repräsentationen werden zu durchsuchende Dokumente in verschiedenen Varianten abgespeichert: Als Original, lemmatisiert und gestemmt.
Im klassischen Information Retrieval wird eine Suche über ein einfaches Keyword matching realisiert. Hierbei wird der Input mit denselben Preprocessing-Mechanismen verarbeitet und die Wörter des Inputs mit den Wörtern in den Dokumenten der Datenbank verglichen. Basierend auf Wort-Übereinstimmung bekommen dann die einzelnen Dokumente einen Übereinstimmungs-Wert zugewiesen (Score). Abbildung 1 zeigt ein Beispiel einer Datenbank mit drei Dokumenten und einer Suchanfrage „die Kanzlerin“. Hier bekäme Dokument 1 einen Score von 3 („Kanzlerin“ kommt 2 mal vor, „die“ kommt einmal vor), Dokument 2 einen Score von 3 („Kanzlerin“ kommt einmal vor, „die“ kommt 2 mal vor) und Dokument 3 einen Score von 1. Dokument 1 und 2 würden demnach ausgesucht werden. Dies ist insofern ungünstig, als dass das Funktionswort „die“ genauso viel Einfluss auf das Retrieval hat wie das wichtigere Inhaltswort „Kanzlerin“. In der Praxis möchte man jedoch typischerweise eher einen Algorithmus, der Inhaltswörter höher bewertet und Dokument 1 auswählt, weil das Wort „Kanzlerin“ hier häufiger vorkommt. Eine Möglichkeit, dies zu beheben, ist das Ausschließen bestimmter Wortarten vom Retrieval. So können z.B. Artikel oder Hilfsverben aus Query und Dokumenten beim Preprocessing gelöscht werden.
Eine andere, weit verbreitete Möglichkeit sind gewichtete Wort-Scores, z.B. auf Grundlage eines tf.idf-Scores. Tf.idf steht für „term frequency/inverse document frequency“ (Term-Häufigkeit/Inverse Dokument-Frequenz). „Wichtigere“ Wörter, wie Inhaltswörter, werden hierbei höher gewichtet als beispielsweise Funktionswörter.
Rechenbeispiel. Der Score berechnet die Wichtigkeit eines Wortes, indem das Produkt der Termhäufigkeit (tf) mit der inversen Dokumentenhäufigkeit berechnet wird. Die Termhäufigkeit gibt an, wie oft ein Wort in einem Dokument vorkommt. Im Beispiel ist die Termhäufigkeit von „die“ für Dokument 1 tf(die, doc1) = 2. Entsprechend sind tf(die, doc2) = 2, tf(die, doc3) = 1, tf(Kanzlerin, doc1) = 2, tf(Kanzlerin, doc2) = 1, tf(Kanzlerin, doc3) = 0.
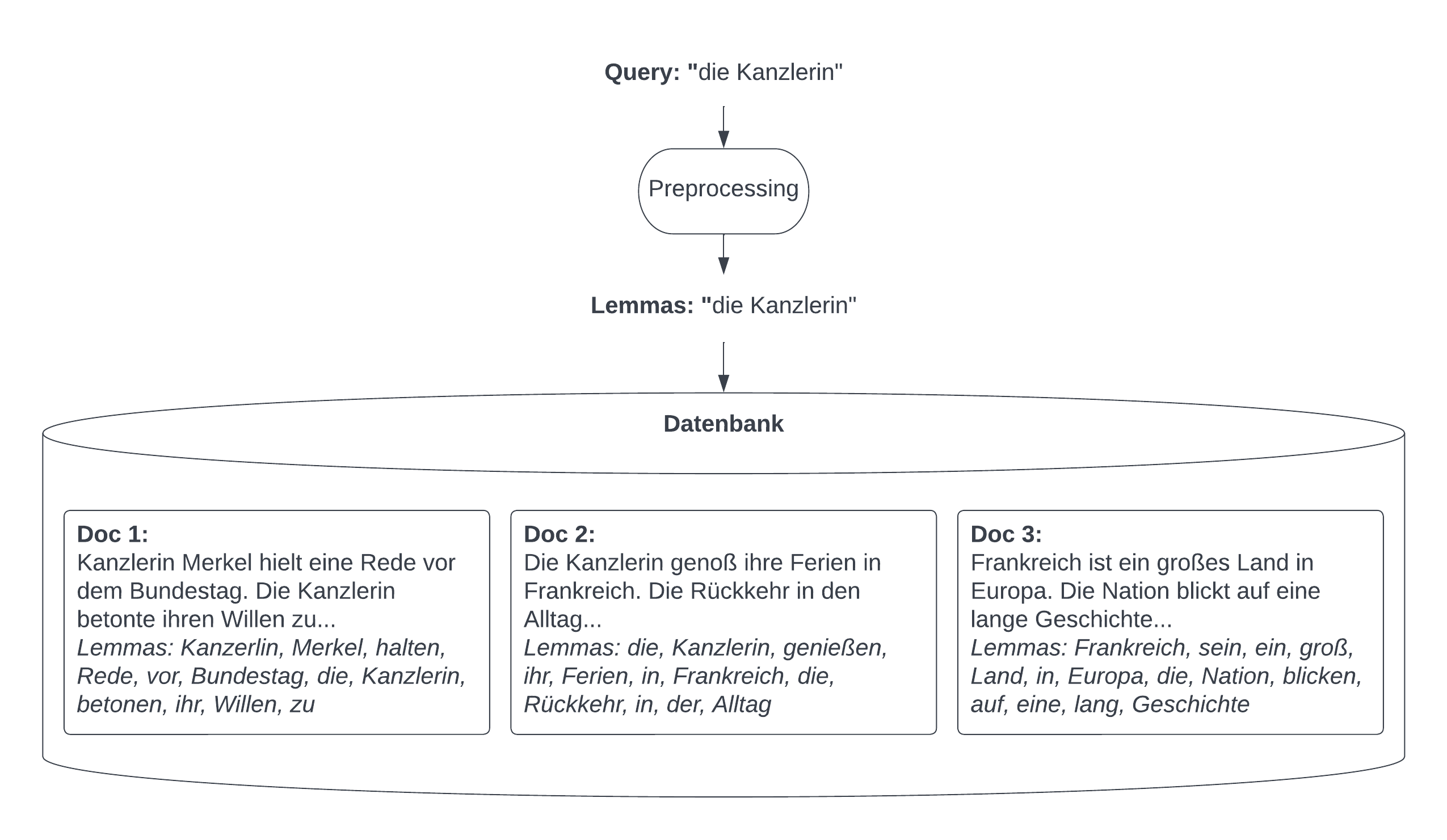
Die Inverse Dokumenthäufigkeit (idf) gibt an, in welchem Anteil der Dokumente ein Wort vorkommt und ist definiert als die Anzahl der Dokumente geteilt durch die Dokumente, in denen ein Term vorkommt. Die inverse Dokumenthäufigkeit von „die“ ist also idf(die) = 3 / 3 = 1 und von „Kanzlerin“ idf(Kanzerlin) = 3 / 2 = 1,5
Auf Grundlage dieser Werte können Scores nun neu berechnet werden. Für die Query im Beispiel und Dokument 1 ergibt sich:
- Tf.idf(die, doc1) = tf(die, doc1) * idf(die) = 1 * 1 = 1
- Tf.idf(Kanzlerin, doc1) = tf(Kanzlerin, doc1) * idf(Kanzlerin) = 2 * 1.5 = 3
Der Score des Dokumentes beträgt damit 1 + 3 = 4. Für Dokument 2 ergibt sich parallel:
- Tf.idf(die, doc2) = tf(die, doc2) * idf(die) = 2 * 1 = 2
- Tf.idf(Kanzlerin, doc2) = tf(Kanzlerin, doc2) * idf(Kanzlerin) = 1 * 1.5 = 1.5
Der Score für Dokument 2 beträgt somit 2 + 1,5 = 3,5.
Ein auf tf.idf basierter Retrieval-Mechanismus kann also Inhaltswörter höher bewerten und würde nun Dokument 1 auswählen, welches einen höheren Score aufweist.
Neuronale Ansätze.
Modernere Ansätze des Information Retrieval benutzen neuronale Netzwerke zur Encodierung von Dokumenten. Hierbei werden in der Regel große neuronale Netze, sogenannte Transformer, auf großen Datenmengen vortrainiert. Der bekannteste Basisansatz solcher Modelle wird als BERT bezeichnet (Bidirectional Encoder Representations from Transformers1), worauf die meisten modernen Retrieval-Methoden basieren. Solche Modelle werden dazu benutzt, einen Text in einen mathematischen Vektor, das heißt eine Liste von Zahlen, umzuwandeln. Das Ziel ist es, ähnliche Wörter mit ähnlichen Vektoren darzustellen. Der Vorteil hierbei ist, dass nicht nur die Oberflächenform der Wörter beachtet wird (wie bei Keyword-basierten Ansätzen), sondern Wörter mit einer ähnlichen Bedeutung auch mit ähnlichen Repräsentationen dargestellt werden.
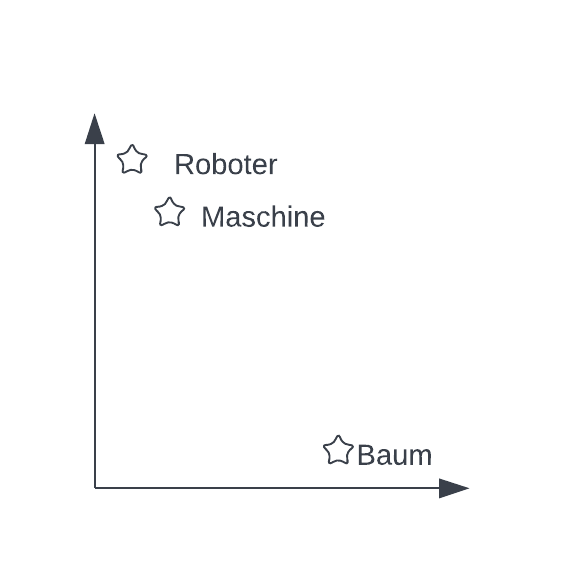
Abbildung 2 zeigt ein fiktives Beispiel. Vektoren können auch als Punkte in einem Koordinatensystem (oder auch „semantischer Raum“) aufgefasst werden. Das Transformer-Modell stellt dabei, wie in der Abbildung zu sehen, ähnliche Wörter als Punkte im semantischen Raum dar, die näher zueinander sind: „Roboter“ liegt näher an „Maschine“ als an „Baum“, „Roboter“ und „Maschine“ sind sich also ähnlicher. Diese Ähnlichkeit kann über die Benutzung der Kosinus-Distanz2 formalisiert werden. Diese Distanz kann zwischen zwei beliebigen Vektoren berechnet werden. Sind sich die Vektoren sehr ähnlich, nimmt die Distanz Werte in der Nähe von 1 an. Sind sie sich unähnlich, geht die Distanz Richtung -1.
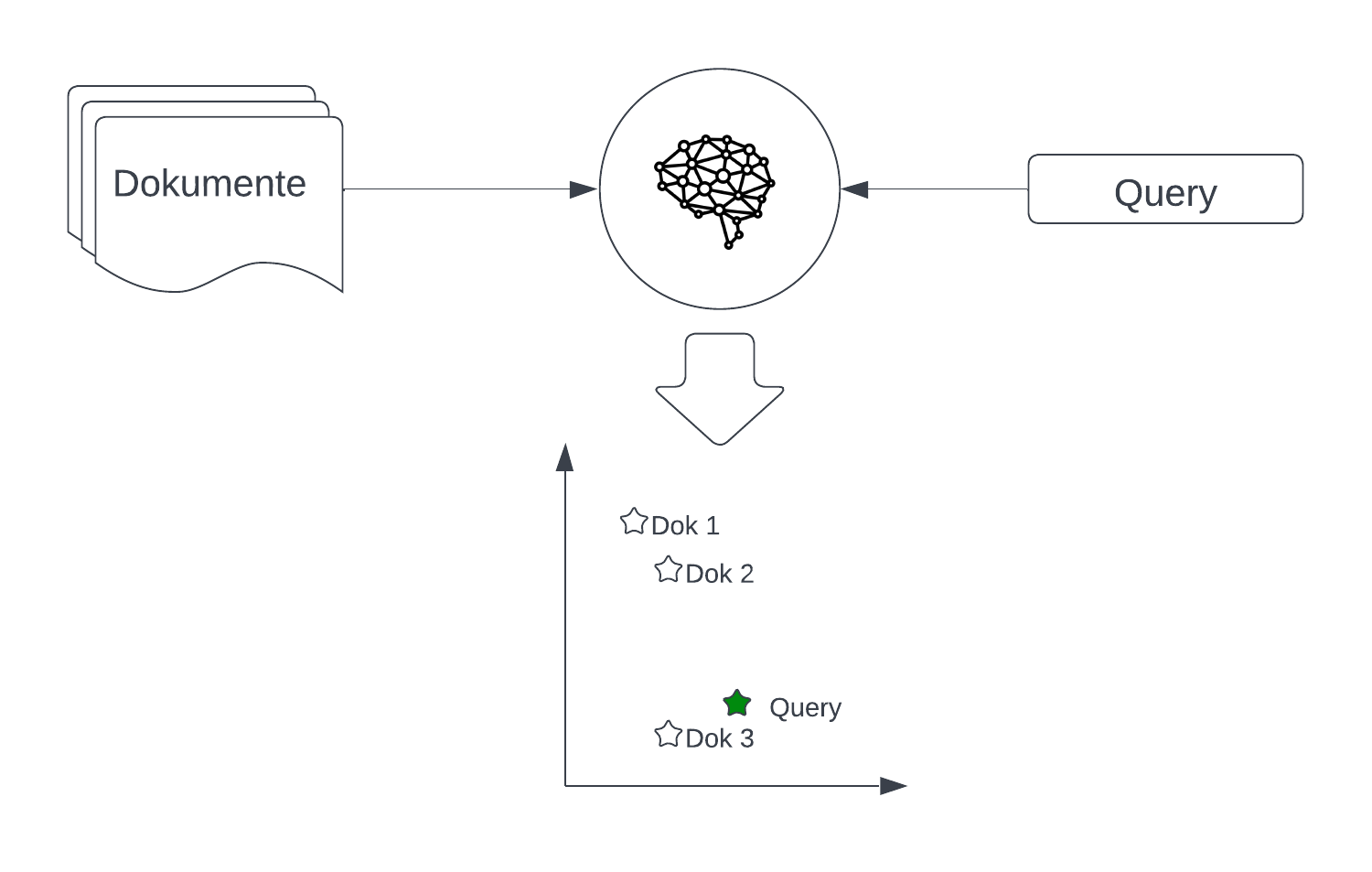
Moderne Retrieval-Modelle benutzen solche neuronalen Netze, um alle Dokumente in einer Datenbank in den semantischen Raum abzubilden. Neben dem Dokument wird dann eine Vektorrepräsentation in die Datenbank geschrieben. Dasselbe Netz kann dann auch genutzt werden, um die Query in den semantischen Raum abzubilden. Danach wird ein Maß wie die Kosinus-Ähnlichkeit genutzt, um das ähnlichste Dokument zur Query zu finden.
Abbildung 3 zeigt ein Beispiel: Das neuronale Netz wird erst genutzt, um die Dokumente 1 bis 3 der Datenbank in den semantischen Raum zu projizieren. Dasselbe Netz projiziert dann die Query in den semantischen Raum. Der Query-Vektor ist klar erkennbar am ähnlichsten zu dem Vektor für Dokument 3. Dieses wird als Suchresultat zurückgegeben.
Weiterführende Technologien
Weiterführende Technologien im Bereich des Information Retrieval beinhalten vor allem komplexere neuronale Netze. Zum Beispiel können verschiedene Netzwerke zur Encodierung von Query und Dokumenten verwendet werden. Ein wichtiger Forschungsbereich ist zudem die Effizienz solcher Modelle. Da die Textdatenbanken, die durchsucht werden sollen, oft Millionen von zu durchsuchenden Dokumenten beinhalten, ist es von größter Bedeutung, die Indizierung und Ähnlichkeitsberechnung schnell und speichereffizient zu gestalten. Methoden wie FAISS3 und Produktquantisierungen4 sorgen für schnellere Zugreifbarkeit und einen geringeren Speicherbedarf.
Auch im klassischen Information Retrieval spielt Effizienz eine Rolle. Hier kommen beispielsweise invertierte Indexe5 zur Anwendung, die für jedes bekannte Wort eine Liste an Dokumenten abspeichern, die das Wort beinhalten, was die Zugriffszeit deutlich verkürzt.
Mögliche Anwendungsbereiche
- Mögliche betriebliche Einsatzbereiche:
- Service, Kundenmanagement
- Forschung und Entwicklung
- Marketing und Vertrieb
- Mögliche Branchen: Informations- und Kommunikationstechnologie, Medien, Einzelhandel, Gastgewerbe, Tourismus
Nutzen und Voraussetzungen für KMU
Methoden des Information Retrieval sind überall dort relevant, wo in großen Text-Datenmengen Informationen gesucht werden müssen, und damit für nahezu alle wirtschaftlichen Bereiche. Ein einfacher Information-Retrieval-Ansatz basierend zum Beispiel auf tf.idf kann in der Regel auch von untrainierten Entwicklern implementiert werden. Für komplexere Methoden stehen vortrainierte Modelle für verschiedene Sprachen auf dem Huggingface-Model Hub6 zur Verfügung, wie z.B. DPR oder das Sentence-Transformers-Package.
Quellenverzeichnis
1. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
2. https://de.wikipedia.org/wiki/Kosinus-%C3%84hnlichkeit
3. https://github.com/facebookresearch/faiss
4. https://www.pinecone.io/learn/product-quantization/